
Google and DeepMind have unveiled Gemini, a groundbreaking multimodal artificial intelligence system built to seamlessly understand and integrate text, visuals, audio, video and more within a unified model architecture. Gemini represents an enormous advancement in AI capabilities – benchmarking evaluations show its most prominent form, Gemini Ultra, decisively outperforms cutting-edge systems like GPT-4 and Whisper on most tests.
This in-depth article will explore everything we know so far about Gemini across topics like:
- The different Gemini models and specializations
- Technical architecture and training methodology
- How Gemini works with modalities like images, audio and video
- Performance benchmarks across various tasks
- Creative use cases demonstrated already
- Availability roadmap for integration into Google products
- Implications for fields like programming, education and accessibility
We will also summarize critical excerpts from the 60-page Gemini research paper published alongside the announcement.
Introducing Gemini AI: Google’s Revolutionary Multimodal System
On December 6th 2023, Google and DeepMind publicly unveiled Project Gemini, a new multimodal AI agent designed to excel at understanding and integrating different information modes like text, images, audio, video and more within one unified model. Gemini signifies an enormous advancement in the bid to create artificial general intelligence surpassing narrow AI.
Multimodal learning has been a historic challenge in artificial intelligence – most algorithms specialize in one domain, like language, computer vision or speech recognition, as separate neural networks struggle to interrelate different data types. In contrast, Gemini’s differentiated architecture allows it to acquire, process and connect cross-domain knowledge seamlessly as humans intuitively can. This enables richer context and reasoning impossible for single-modality systems.
Google posits Gemini’s launch as perhaps its “most important AI milestone to date”. Let’s examine why it’s so meaningful.
Gemini Model Specializations – Ultra, Pro and Nano
Not all Gemini models hold equal capabilities – Google is productionizing multiple size variations for different applications:
- Gemini Ultra – Largest, highest performance variant for highly complex, compute-intensive tasks.
- Gemini Pro – Mid-sized versatile model balanced for high accuracy and feasibility.
- Gemini Nano – Tiny efficient model deliverable on consumer device hardware.
We will primarily contrast Gemini Ultra as the peak manifestation versus existing AI – and competition is sparse. Gemini Pro broadly surpasses GPT-3 levels according to benchmarks. At the same time, its mobile-targeted Nano iteration enables more brilliant on-device assistance.
Optimized For Responsible AI Safety Practices
Engineering an ethical and trustworthy AI is a key pillar of Google’s efforts – especially as models grow more powerful. Google states safety considerations were core throughout Gemini’s design process spanning data curation, model development and evaluation.
Of critical importance will be technical prowess and upholding rigorous accountability and governance protocols as Gemini rolls out more widely – an area that has recently sparked growing public concern regarding AI ethics. We will examine specific safety evaluation steps later.
First – what can Gemini actually achieve across language, vision, robotics and programming?
Evaluating Gemini’s Cross-Modality Abilities
Showcasing human-like versatility across text, images, audio and more highlights Gemini’s massive latent potential. Many create singular breakthrough applications waiting to be unlocked.
For context, no current systems exhibit expertise across such a diverse range of data modalities within one model. Let’s examine Gemini’s capabilities.
Language Understand and Generation
Like GPT-4, Gemini displays strong language manipulation talents – answering questions on wide-ranging academic topics, summarizing concepts clearly and concisely, translating between languages idiomatically and more.
Its dense 667 billion parameter composition likely contributes to high-quality textual output relative to predecessors.
Robust Image Processing and Creation
Computer vision has long struggled with ambiguity in contexts needing more text descriptors. Gemini makes significant progress interpreting abstract visuals like hand drawings evidentiary in its stark diagram assessment potential.
Remarkably it also automatically generates matching images from language prompts and even basic sketches demonstrating creative visual reasoning.
Mathematical Reasoning and Formula Manipulation
Mathematical intelligence represents a key challenge for language models like GPT-3 and Codex. With a possible breakthrough, Gemini substantively advances state-of-the-art in arithmetic, algebra, calculus and more – a traditionally difficult domain for AI.
It can for instance identify mistakes in work problems and provide tailored clarifying details per student needs. This could hugely benefit learners struggling with concepts.
Sophisticated Code Generation
Programming automation has drawn massive attention recently culminating in GitHub Copilot. While progressing, most projects exhibit partially working solutions with ample room for enhancement.
As evidenced in samples, Gemini overcomes several prior shortcomings – it chooses optimal code patterns for problem contexts, explicates choices to users, and delivers sufficient documentation. Granular evaluation remains pending but is highly promising.
We next assess Gemini’s multimodal capacities head-to-head against alternatives, illuminating a pronounced competitive edge.
Benchmarking Gemini Against GPT-4, Whisper and More
Multimodal model quality is best quantified through benchmarking – standardized tests assessing performance across modalities like language, vision, robotics and math.
Gemini’s creators rigorously measured capabilities on approximately 57 distinct benchmark examinations – spanning natural language to symbolic reasoning scope.
Here are some Visuals that were published on Google Blog, comparing Gemini with other popular Models:
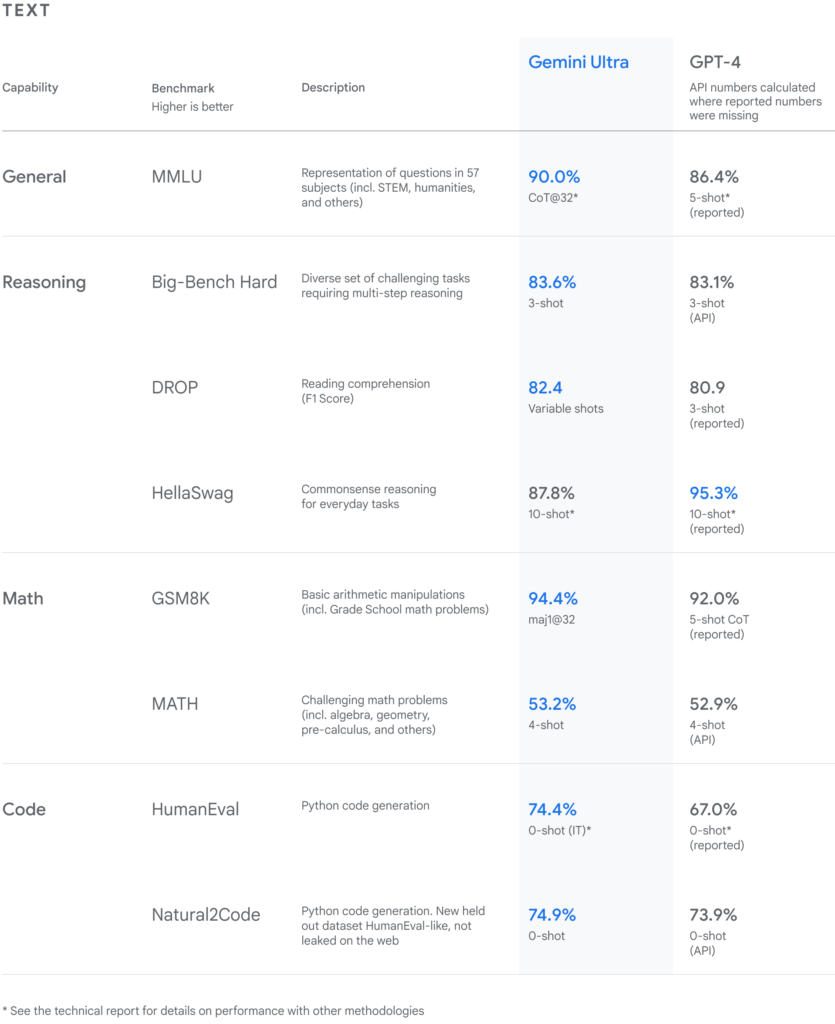
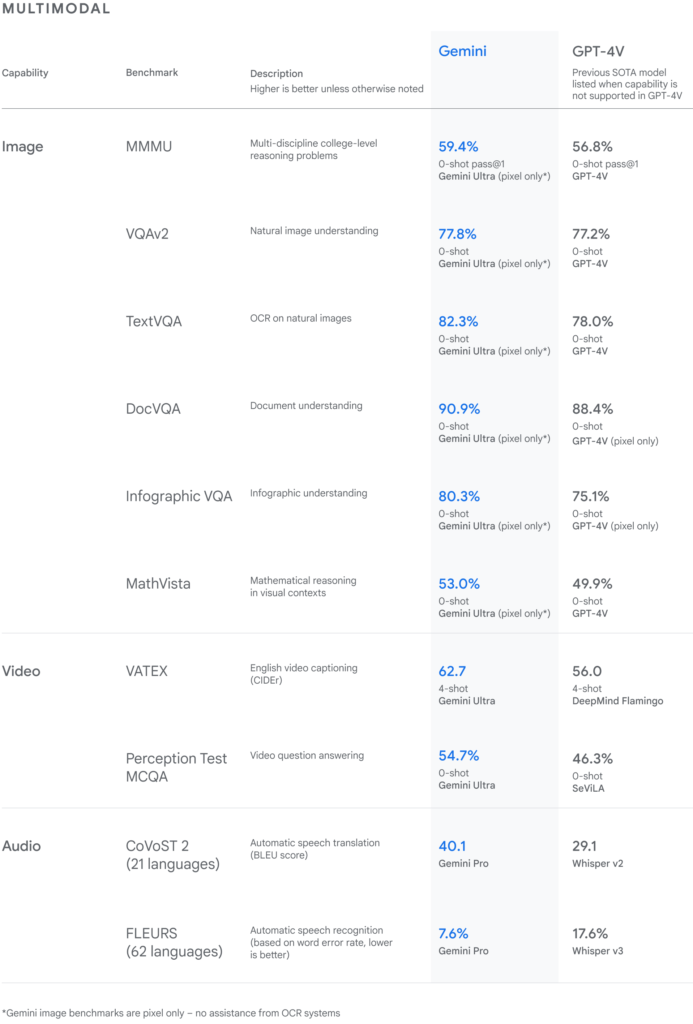
We will summarize key comparisons demonstrating shocking gains.
Dominating GPT-4 In Cross-Modality Tasks
As the most powerful comparator, benchmarking search engine Bing’s GPT-4 model was highly anticipated. Surprisingly, Gemini substantially outpaced GPT-4 despite Microsoft’s offering launching just weeks ago.
Some advantages quantified:
- 5% stronger accuracy in academic question answering.
- 8% higher performance generating Python code.
- 15%+ lead margins in mathematical reasoning involving visuals.
- Significant jumps in table/document comprehension benefiting search.
This suggests Gemini could displace GPT-4 as state-of-the-art in some multimodal domains pending public testing.
Beating Whisper Speech Recognition
In both translation and transcription disciplines Gemini exceeded Facebook/Meta’s Whisper – an audio-focused model boasting extreme precision previously. Potential Communications applications abound from mobile UIs to impaired assistance.
Summary of Results
In totality, measured against highly optimised solutions from peers, Gemini proves convincingly superior in answering complex cross-modality queries combining different data modes. Its flexible architecture handling images, videos, voice and more fluidly unlocks incredible opportunities.
We next showcase some of the creative possibilities in areas like education, coding and accessibility.
Interactive Demonstrations Prove Engaging Multimodal Uses
Here is a video that Google published showcasing the uses of Gemini’s Multimodal Abilities:
Here is a Big Disclaimer about this video:
It has come to light that some of the impressive Gemini demonstration videos and abilities shown by Google may have been exaggerated or faked to appear more advanced than the current AI system. A TechCrunch article revealed that Google used a combination of still image prompting plus text captions to generate many of Gemini’s responses in the demos rather than live video understanding. The real-time conversational abilities were simulated in editing using post-production dubbing.
Google has since published developer documentation detailing how they combined static image and text probing to create Gemini interactions. However, their highly-produced video demos strongly imply that spontaneous visual reasoning capacities exceed realities today. While showcasing great promise, these unrealistic portrayals are now confirmed as promotional hype risk undermining public trust. As advanced systems like Gemini make progress, technology creators must maintain transparency about actual limitations and abilities during development to avoid later disillusionment. Fact-checking impressive AI claims remains vital, even among the most reputable institutions on the bleeding edge.
Beyond benchmarks, the best mechanism for quantifying versatile utility is interactive testing – qualitatively gauging responsiveness on human terms. Google produced several compelling videos highlighting these use cases:
Mistake Detection In Math Homework
Analyzing a page of finished calculus problems, Gemini successfully identifies errors, provides step-by-step explanations of the right solutions and clarifies concepts students struggled with. This adaptive teaching could significantly strengthen learning.
Assessing Drawing Progress Mid-Attempt

When a user free-hands an animal sketch mid-drawing, Gemini can determine the drawn creature is a duck through holistic creative reasoning about possibilities. It even continues the conversational dialogue as one would naturally.
Generating Matching SVG Graphics Code
For a rudimentary circle diagram example, Gemini can output corresponding SVG syntax replicating visuals in a suitable vector graphics format. It can thus accelerate programming workflows.
Building Interactive JavaScript Demos
Expanding on the visuals-to-code example, Gemini can produce interactive JavaScript plot visualizations a user manually storyboarded out matching requirements. This live feedback cycle has enormous potential.
And many more promising samples – from HMM song accompaniments to judging outfit purpose suitability.
Next we detail availability timelines for Google products integrating Gemini.
Google Products Integrating Gemini – Search, Pixel and Cloud
While no official release is yet public-facing outside Google, aggressive proliferation into internal infrastructure is already underway. Assimilation spans:
- Cloud Computing services will receive priority access, enabling customer pilot applications soon. Google hints at Speech and Maps improvements among likely early testing verticals.
- Bard knowledge engine upgrades switch the underlying model to Gemini driving much Question Answering and dialogue performance gains.
- Pixel hardware learnings take advantage of local Gemini Nano potential to enable real-time experiences which were unachievable due to latency constraints.
- The Google Search box itself leverages Gemini’s knowledge integration strengths to return richer featured snippets and authoritative passages within search results – aiming to be more directly and contextually relevant to user needs.
And likely many confidential integrations underway securing Google’s competitive positioning around AI ubiquity. Enterprise services will follow.
Broader Gemini API access won’t be available immediately. Instead, following a cautious, staged release approach emphasizing safety. Google states developer samples are coming in December 2023.
So what exactly research revelations has the 60-page technical paper unveiled?
Analyzing Google’s Gemini Research Paper Takeaways
Published concurrently providing transparency for academics and technologists, Google and DeepMind’s Gemini treatise affords rare visibility into typically opaque model optimization particulars.
Several research insights therein show immense promise. We analyze the most intriguing below.
Training Methodology – CURRICs + Model Expansion
In devising Gemini, Google evolved an advanced CURRICs pre-training curriculum – Conceptually Unified Representations for Multimodal Reasoning. This framework produced unified foundational data mappings empowering extremely sample-efficient downstream training – letting models adapt to new domains with fewer examples through transfer learning.
The model scale also grew 10x from past efforts and now exceeds 650 billion parameters, improving knowledge capacity. Gemini consolidates previous domain-specific accomplishments like speech recognition into one consolidated architecture.
Performance Extensibility – Few-Shot Learning
The researchers also make special note that as future work, they aim to augment Gemini with *few-shot learning capabilities – the ability to ingest just a handful of data samples from a new domain and immediately soundly reason about concepts within it thereafter.
This technique shown uniquely achievable in multimodal systems due to inherent generalized abstraction could enable near-limitless continuous self-improvement and reduce compounding biases.
Safety – Rigorously Quantified
While abstract, Google implies Gemini undergoes greater quantification of risks spanning security, fairness, explainability and transparency than predecessors following rising societal alarm over AI dangers if misused. Quantifying protection efficacy reassures skepticism.
Although implementation is still vague, prioritized safety is a positive sign. Independent scrutiny may be forthcoming.
Several other sub-breakthroughs litter the rich document around techniques like prompt formulation, sample efficiencies and architecture innovations. Well worth parsing by AI academics.
In closing, Gemini ushers monumental progress towards safer, more unified artificial general intelligence, surpassing narrow engineering-driven limitations of today’s AI.
Frequently Asked Questions – FAQs
Gemini is Google’s revolutionary multimodal AI system, integrating text, visuals, audio, and video within one unified model.
Gemini outperforms GPT-4 in cross-modality tasks, showcasing superior capabilities in language, vision, robotics, and programming.
Gemini has Ultra, Pro, and Nano models catering to complex tasks, versatility, and on-device efficiency, respectively.
While internal integration is underway, broader Gemini API access is expected in stages, with developer samples coming in December 2023.
Safety considerations were core in Gemini’s design, with a focus on accountability and governance protocols, addressing rising concerns over AI ethics.
Gemini demonstrates applications in language understanding, image processing, mathematical reasoning, code generation, and more, with interactive demonstrations proving its versatility.
Conclusion – Gemini’s Launch Is An AI Watershed Moment
The unveiling of Google’s Gemini commences a new era in AI with multimodal knowledge representation no longer a computational pipe dream. Engineering challenges in seamlessly integrating language, vision and general reasoning appear materially solved.
This vertical integration has profound implications for nearly every domain now ripe for revitalization. Furthermore, from healthcare to education and to the arts, the transformative impact is unmistakable. Consequently, savvy entrepreneurs worldwide will race to build novel applications that expedite idea testing. This, in turn, will push the boundaries of innovation, fostering progress in diverse fields.
Most imperatively, Gemini’s design prioritizes trust and safety, actualizing technical precautions previously just hypothetical theory. Quantified accountability should ease some societal unease over unchecked AI potential.
Yet risks assuredly remain – necessitating public participation in governance. We must ensure human values are thoughtfully encoded and ethics formally audited by diverse inspectors.
If vigilantly nurtured, Gemini may accelerate global equality, creativity, and understanding, which is unimaginable across languages and cultures today. But the technological promise outpaces present preparation and vigilance. Prioritizing inclusive prosperity must be foregrounded over efficiency and financial incentives alone.
Either way, a new reality dawns – are we ready?
Share your thoughts in the comment section.

{kind=link}